Postgres – vsetko, co si chtel vediet, ale bal sa spytat svojho seniora, aby si nevypadal ako jelito 01. Architektura, procesy, pamat.
…
Cluster
Po instalacii postgresu vznika na FS DB cluster, obvykle u RHEL v /var/lib/pgsql/ (to je umiestenie dat, nie binarok!; $PG_DATA). Cluster je to nazyvane preto, pretoze tam su sustredene vsetky – defaultne i uzivatelske databaze, vid obrazok (prevzate z prezentacie Stehuleho). V funkcneho hladiska sa da cluster definovat ako vsetko, co je pristupne cez jednu IP na jenom porte (z toho napr. vyplyva, ze viac clusterov na jednej IP musi mat minimalne rozdielny port).

Ako sa to prejavi na systemovej urovni?
- Cluster = adresar, typicky nazov podla verzie postgresu, tzn. /var/lib/pgsql/11
- Databaza = adresar, napr. var/lib/pgsql/11/data/11657/
- Tabulka = subor
NIKDY, opakujem, NIKDY nepresuvajte tabulky a databaze rucne v ramci FS, inak sa stratia metainformacie. Presunut cely cluster (pri vypnutom DB serveri) je mozne.
- DB postgres – vzdy som si myslel, ze tu sa nachadza systemovy katalog clusteru, ale neni to tak, systemove katalogy ma kazda databaza zvlast. Je v pohode mozne tuto databazu zmazat, je tam len preto, aby clovek, ktory sa pripaja, nemusel vediet nazvy databaz a pripojil sa “defaultne” k postgresu.
- DB template1 – “template” pre prikaz CREATE DATABASE; Je mozne template1 upravit a ziskat customizovanou tempaltu pre vsetky nove databaze vznikajuce v ramci clusteru.
- DB template0 – neni mozne upravovat. Je templatou pre template1, aby bolo mozne vratit sa do vychodzieho stavu, ked sa nieco pokurvi pri editacii template1.
- DB users su useri v ramci celeho clusteru, t.j. nie su viazani na konkretnu DB. Napr. userom postgres je mozne pripojit sa na vsetky DB.

system katalog
Je podobne, ako u oraklu, katalog stavu clusteru. Su tu info a metainfo o clusteri, kroz vsetky schemy a databazy. Ide vlastne o obycajne postgresove tabulky, ale obycajne sa needituju rucne. Zacinaju prefixom “pg_” a ich kompletny zoznam jest tu v docu. Napr tabulka pg_databases je zoznam vsetkych databazi v clusteri.
schemas
Schemy nie su nic ine, nez namespacy v ramci databaze. T.j. i v ramci 1 databaze mozu byt objekty (tabulky, indexy…) stejneho nazvu, ale v inom namespace. Defaultne, pokial sa schema explicitne nedefinuje, sa vytvaraju objekty v scheme public.
tablespaces
Su fyzicke kontajnery pre data (databazy, tabulky, indexy, etc…), z hladiska OS vlastne adresare. Ich vyznam – napr. pokial sa zaplni partisna s postgresom, je mozne urobit novu tablespace nad inou partisnou a pokracovat. Pri vytvarani tablespace sa vzdy musi uviest full path v ramci filesystemu a systemuser postgres MUSI BYT VLASTNIKOM TOHOTO ADRESARA!!! Nepomaha ani chmod 777!
Tablespace moze patrit niekolkym databazam a databaza moze mat niekolko tablespaces = nezavislost logickych a fyzickych databazovych struktur.
Po instalacii sa vytvaraju defaultne 2 tablespace – pg_global a pg_default.
Bez zastavenia serveru nie je mozne menit adresar pre tablespace. Objekty (napr. tabulky) je mozne presuvat medzi tablespacema.
SELECT spcname FROM pg_tablespace; – vylistovanie vsetkych tablespaci
SELECT tablespace FROM pg_tables WHERE tablename = ‘NAZOV_TABULKY’; – zistim, do akeho tablespace patri konkretna tabulka
Najlepsia vec na postgrese je to, ze sa tablespacy standardne nepouzivaju. Nemaju vlastne vyznam a tak sa na ne vykaslite. Ono ani v Oracle sa to nepouziva k nicomu inemu, nez k obmedzeni velkosti DB via obmedzenim cez tablespace.
subory
subory a adresare v $PGDATA su detailne popisane v docu.
postgresql.conf – hlavny konfigurak serveru, tu aj cesty k datafiles a binarkam a pod.
pg_hba.conf – definuje sposoby autentikacie klientov a definuje klientov, ktori sa ku clusteru mozu pripajat.
pg_ident.conf – definuje mapovanie lokalnych uctov na postgres ucty
postmaster.opts – zapis parametrov, s ktorymi bol Db server naposledy spusteny
tabulky a indexy (v postgres terminologii relation) su storovane v datafiloch v adresari /base a maju cisla podla OID databaze. Datafile (nazyvany aj segment) moze narast do 1GB (pri builde ./configure –with-segsize), potom je zalozeny dalsi so sufixom. Kazdy datafile ma 3 subory, napr. 14327, 14327_fsm (free space map) a 14327_vm (visibility map).
SELECT pg_relation_filepath(‘NAZOV_TABULKY’); – vylistuje subor segmentu, kde sa tabulka nachadza
adresare
/base – tu su subory per-database (hlavne datafajly)
/global – subory pre cely cluster, napr. tabulky pg_database, pg_control a pod.
/pg_tblspc – symbolicke linky na tablespaces….
databaze
Po instalacii su defaultne nainstalovane 3 databaze: postgres, template0 a template1.
Postgres je tam preto, pretoze niekam sa musis prihlasit, ked sa ku clusteru pripajas a pokial nevies, ake su tam databaze, tak postgres je sazka na jistotu. POZOR! Postgres nie je systemovy katalog, kazda databaza ma vlastny systemovy katalog. Je mozne databazu postgres bez strachu zmazat a ideme dalej, ale obvykle sa to nerobi.
Templaty (template0 a 1) sa pouzivaju ako predlohy pri vytvarani user databaz. Preto sa instalacii postgresu hovori cluster, pretoze je tam hned niekolko databazi :). Template1 je predloha pre prikaz CREATE DATABASE a je mozne ju kustomizovat, cimz sa vytvori pekna sablona pre moje potreby. Template0 je needitovatelna a sluzi na obnovu template1, pokial si ju dokurvim.
Locales
Locale je nadefinovane zvlast pre cluster i pre databazu, locale clustru a encoding databaze sa musia zhodovat!
Pro instalacii clusteru prepinace –locale=LOCALE a –encoding=ENCODING.
Overenie: SELECT UPPER(‘Ej, zmätene hľadím až na Štrbskô pleso’);
tabulky – struktura
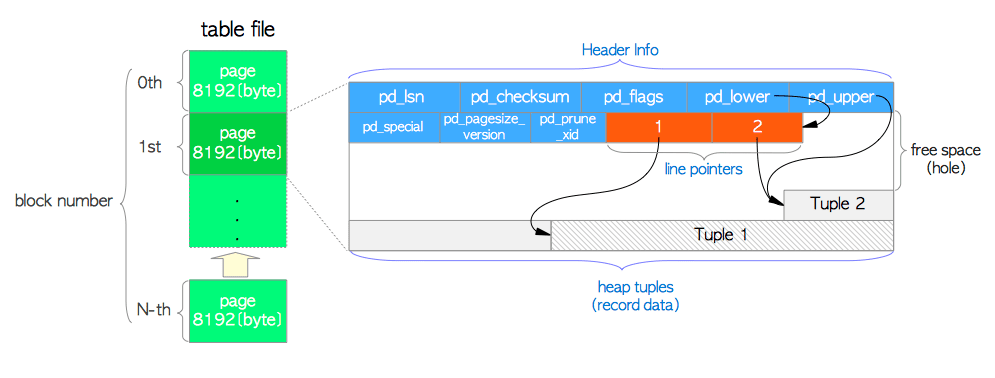
Pod tabulkou je myslena typicka heap tabulka. Tabulka a indexy su sucastou datafajlu (casto nazyvane page). Datafajl je sled datovych blokov, kazdy 8192 B velky a cislovany sekvencne (od 0). Ked sa datafajl zvacsuje, tak sa proste na jeho koniec pridavaju nove bloky/pages. Kazdy zaznam v tabulke (record/tuple) sa musi vojst do bloku/page. Ak je vacsi, pouzije sa specialny mechanizmus TOAST.
Blok ma 3 casti: header (popis bloku), pointery (ukazuju na data v tuples) a tuples (vlastne samotne data). Najdolezitejsim udajom v headeru je pd_lsn – je to ukazatel na odpovedajuci identifikator vo WAL logu.
V pripade, ze za cita z datafajlov tak pripadny index procesu vlastne len povie “pozadovane data su v bloku X a v tuple Y”.
indexy – typy a struktura
Indexov ako maku, od klasickych (hash, Btree) az po mne nezname (GIN, RUM a pod).
perfektny serial o indexoch od Jegora Rogova.
procesy

Po nastartovani posgresu sa spusti hlavny proces, ktory spusta background procesy (checkpointer, writer, wal writer, autovacuum launcher, stats collector, bgworker/replicator, logger, archiver). Okrem toho kazda koneksna do DB (klientsky dotaz) sposobi fork postgresu.
ps -ef | grep postgres
postgres 941 1 0 Jul08 ? 00:00:01 /usr/lib/postgresql/10/bin/postgres -D /var/lib/postgresql/10/main -c config_file=/etc/postgresql/10/main/postgresql.conf
postgres 954 941 0 Jul08 ? 00:00:00 postgres: 10/main: checkpointer process – cekpointy dat
postgres 955 941 0 Jul08 ? 00:00:00 postgres: 10/main: writer process – dirty data z shared buffru su zapisovane na perzistentnu storage
postgres 956 941 0 Jul08 ? 00:00:00 postgres: 10/main: wal writer process – zapisuje do wal logov
postgres 957 941 0 Jul08 ? 00:00:01 postgres: 10/main: autovacuum launcher process – spusta vacuum
postgres 958 941 0 Jul08 ? 00:00:01 postgres: 10/main: stats collector process – zhromazduje statistiky o databazi a zapisuje ich do pg_stat_database a pg_stat_activity
postgres 959 941 0 Jul08 ? 00:00:00 postgres: 10/main: bgworker: logical replication launcher
postgres 960 941 0 Jul08 ? 00:00:00 postgres: 10/main:archiver process – pokial je zapnuty archivny mod, tak archivuje wal logy
Bacha, nikdy napouzivat kill -9 s umyslom zastavit jeden proces – toto restartne cely server, i ked umysel bol len odstrelit jeden proces (napr. nejaky dlhy select). Obecne vzate je spatnou filozofiou zastavovat databazove procesy prostriedkami OS, miesto toho radsej priamo DB prostriekami. Priklad – nejaka koneksna/proces vyziera moc pamate a chcem ju zastavit:
lognutie do DB
SELECT * FROM pg_stat_activity WHERE state = 'active';SELECT pg_cancel_backend(<pid of the process>) - ukoncuje query alebo SELECT pg_terminate_backend(<pid of the process>) - pozor, ukoncuje sessnu
pgbouncer
Problem s pamatou posgresu suvisi s tym, ze kazda nova klientska koneksna odstartuje novy proces (master daemon sa forkne) a pokial to ide takto dalej, tak dojde pamet (nejde totizto o thready, ale procesy). Mnozstvo paralelnych koneksn povoluje parameter max_connections v hlavnom konfiguraku a defalutne je 100. Postgres neponuka nativne ziadny pooling/dispatcher mechanizmus pre pripajanie klientov a preto bola zrodena utilita pgbouncer.
pamet

Naprosto skvely prehladovy clanok o pamatovych strukturach postgresu je na tomto blogu, ja som si urobil niekolko vypiskov. Tento cheatsheet je rozsiahlejsi a su tam aj doporucenia na analyzu.
Su dve pamete – Local Memory Area (pre background procesy; kazdy novy proces si vytvori vlastne chlieviky, ktore su na obrazku) a Shared Memory Area (zakladna pamet serveru, ktora sa alokuje po jeho nastartovani). SMA si nieco ukroji z RAMky a pokial je nastavena spatne (moc velka), tak postgres pochopitelne ani nenastartuje a zapise problemy s pamatou do logu.
LMA: Je typicky pamat pre dotazy uzivatelov. work_mem (sorting ORDER_BY a hlavne joiny tabuliek); maintenance_work_mem (vacuum a pod); temp_buffers – ukladanie temporary tables a tak.
SMA: shared_buffer_pool (najdolezitejsia vec, hlavna pracovna pamet pre server, postgres tu po starte naloaduje tabulky a indexy z persistent storage a pracuje s nimi, zmena vyzaduje restart serveru); WAL buffer (pamet pro pracu s wal logmi); CommitLog (udrzuje v pamati stav transakcii).
Jak sa pamet nastavuje (podla dolezitosti)?
Shared buffers – najdolezitejsie pre vykon serveru. Idealne je mat vsetky datove struktury, ktore server vyuziva, v pameti a netahat to z disku. Vseobecne doporucenia: do 2GB RAM shared buffers asi 1/5 pamete; do 32 GB RAM shared buffers 1/4 pamete; nad 32GB RAM staci shared buffers 8GB. Vykonnostne nema vyznam zvysovat shared buffers nad 20GB (informacia od Stehuleho).
Work_mem – pozor, nastavena velkost moze byt (a bude) v reale multiplikovana poctom sessions. Ak pamat nestaci, bude sa zapisovat do temporary log files, coz sa da odhalit v logu a pamet zvysit. T.j. postup: nastav work_mem na 32MB, nechaj to bezat a proved EXPLAIN ANALYZE, jukni do logov a pokial uvidis zapis na disk (sort method:…. Disk) a pokial to zapisuje do temporary files na disku, zvys work_mem. Temp files maju urcitu mennu konvenciu – PID procesu, ktory ich vyvara a “.0-9”. Da sa podla toho identifikovat, ktory proces (dotaz) zere pamet.
Maintenance_work_mem – robi uklid (vacuum) a mala by byt vacsia, nez work_mem. Obecne sa nastavuje na 10% RAM a pokial su vakuovacie problemy, tak sa zvysi.
Temp_buffers – neviem, nastavuje sa to na 8MB
Kesovanie vsetkeho
Dolezita vec z hladiska vykonu a nastavuje ju parameter effective_cache_size. Pozor, nie je to parameter pre zavazne alokovanie pamete, len odhad toho, kolko bude kesovat Postgres v RAM. Podla toho sa query planner rozhoduje, ci mu exekucny plan vojde do pamete, alebo nie. Obecne sa to dava na 50% RAM.
Kes je hrozne dolezita z hladiska vykonu a Postgres ma na to statistiky (pg_statio_user_tables). Obecne plati, ze pokial je pocet readov z pamate (kese) vacsi, nez pocet readov z I/O (disku), tak je to dobre a vice versa. Dolezite 2 columny:
basix s psql
psql connecting to database:
psql -h HOST -d DATABASE -U user
Quick cesta je psql postgres postgres = pod uzivatelom postgres sa konektni na postgres, predpoklad je, ze root sa nemusi autentizovat. Po defaultnej instalacii postgresu je v OS vytvoreny uzivatel postgres, ktory sa prihlasi do Db serveru bez kredentials
vylistovanie databazi v systemu \l
psql rychly switch na inu DB \c NAZOV_DATABAZE
zoznam tabuliek v databaze \dt
zoznam userov v databaze \du
zoznam funkcii v dtabaze \df
describe tabulku \d NAZOV_TABULKY
edituj komand vo svojom editore \e COMMAND
ine uzitocne prikazy
SELECT pg_reload_conf(); – reload instancie po zmene hlavneho konfu, neni nutny restart
SHOW server_version; alebo SELECT version(); ukaze verziu DB servra
sudo -u postgres psql -c “SHOW data_directory”; – ukaze data directory
Ad Pgbouncer:
1. Každé spojenie do databázy (hanshake, šifrovanie a pod.) si vezme tak 10 MB, preto je pgbouncer doležitý
2. Hlavný konf je pgbouncer.ini
3. Okrem spojenia s databázou sú najdoležitejšie parametry max_client_conn a default_pool_size – https://pgbouncer.github.io/config.html#max_client_conn
4. kúzelná formulka znie max_client_conn + (max pool_size * total databases)
5. https://www.depesz.com/2012/12/02/what-is-the-point-of-bouncing/
dobo
23 Jul 19 at 10:30
Kompletně a skvěle vysvětlený pgbouncer na těchto 2 webech:
https://heap.io/blog/engineering/decrypting-pgbouncers-diagnostic-information
https://hackernoon.com/understanding-postgres-connection-pooling-with-pgbouncer-unlisted-draft-bdb7ebf073ab
ďobo
23 Jul 19 at 14:04
Ako si vyexportovat SELECT do CSV suboru, dva sposoby:
1.:
psql -d dbname -t -A -F”,” -c “select * from TABULKA” > output.csv
2.:
Log do DB a potom
\copy (SELECT * from users) TO ‘/tmp/output.csv’ WITH CSV;
ďobo
5 Aug 19 at 13:21
Jedna z možných konfigurácíí pgbounceru pre veľké prostredia:
1. je vystavený na samostatnom proxy servri, ktorý odchytáva pripojenia a zprostredkuje ich na DB server. T.j. userom (napr. analytikom) sa dá len názov hosta (= proxyna) a databázy – pg bouncer na hostu to pekne predá ďalej na na správny db server.
2. Na proxyne sa vytvori lokálny účet, na ktorý sa budú užívatelia DB mapovať (napr. app_pgbouncer) – neni nutno potom zakladať užívateľov priamo v DB.
3. Je možné urobiť aj mapovanie názvov DB – užívatelia sa hlásia k DB “moja”, ale pgbouncer to prekladá na názov DB “juchuchu”.
4. Všetko je to ošéfované v pgbouncer.ini, príklad jednoriadkového konfigu:
moja = host=10.34.22.2 port=5432 dbname=juchuchu max_db_connections=10 auth_user=app_pgbouncer
ďobo
12 Aug 19 at 11:38
reload konfigu (postgresql.conf) bez nutnosti restartnut DB>
1. SELECT pg_reload_conf();
2. /usr/bin/pg_ctl reload
dobo
1 Oct 19 at 8:28
pamatove struktury postgresu – prehlad:
https://www.postgresql.fastware.com/blog/back-to-basics-with-postgresql-memory-components
ďobo
6 Nov 19 at 14:29
pgbouncer quick how to
https://www.pgbouncer.org/usage.html
ďobo
23 Dec 19 at 14:42
cluster = je adresar
databaza = je adresar
Zmatenie jazykov – templaty, schemy, instancia a clustry su uplne nieco ine, ako v Oracli
dobo
10 Mar 20 at 11:00
select * from information_schema.columns where column_name = ”; – zoznam vsetkych columnov v DB. T.j. pokial nevies, v akej tabulke mas stlpec, na ktory si pamatas, tak timto to rychlo vyfiltrujes
ďobo
11 Mar 20 at 9:19
ak sa chces nieco dobre naucit, spustaj psql s prepinacom -E
Ukaze ti, aka SQL syntax je na pozadi za psql prikazmi
ďobo
11 Mar 20 at 9:22
keby niekto nedajboze instaloval postgres na Windows, tak je obtiaz vzdy z locales, preto:
#windows
CREATE DATABASE abcd with
TEMPLATE = template0
ENCODING = ‘UTF-8’
LC_COLLATE = ‘cs-CZ’
LC_CTYPE = ‘cs-CZ’;
Peter
15 Jan 21 at 9:42
obecne a pekne vysvetlena pamet na postgrese
https://severalnines.com/database-blog/architecture-and-tuning-memory-postgresql-databases
pista baci
12 Feb 21 at 7:51
Export celej DB, len DDL:
pg_dump –schema-only –no-owner NAZOV_DB > DB_export.sql
dobo
22 Jun 22 at 12:00