Postgres – vsetko, co si chtel vediet, ale bal sa spytat svojho seniora, aby si nevypadal ako jelito 13. Query processing.
Spracovanie SQL dotazov je jednou z najkomplikovanejších vecí vôbec. U postgresu neni možné používať hinty a optimalizátor dotazov je cost-based.
Postup zpracovania query
- parser – rozdelí dotaz do tzv. parsovacieho stromu
- analyzer – urobí sémantickú analýzu dotazu
- rewriter – preloží parsovací strom podľa pravidiel v pg_rules
- planner – vytvorí prevádzkový plán dotazu (zvolí access path). To je presne to, čo dostaneš, keď použiješ EXPLAIN
- executor – sjede dotaz podľa plánu a vráti výsledok.
Ide plán “odspoda” (resp. od listov toho, čo vydíš v EXPALINe a prevádza ho až po root plánu). Oprava – viz koment P. Stehuleho pod článkom.
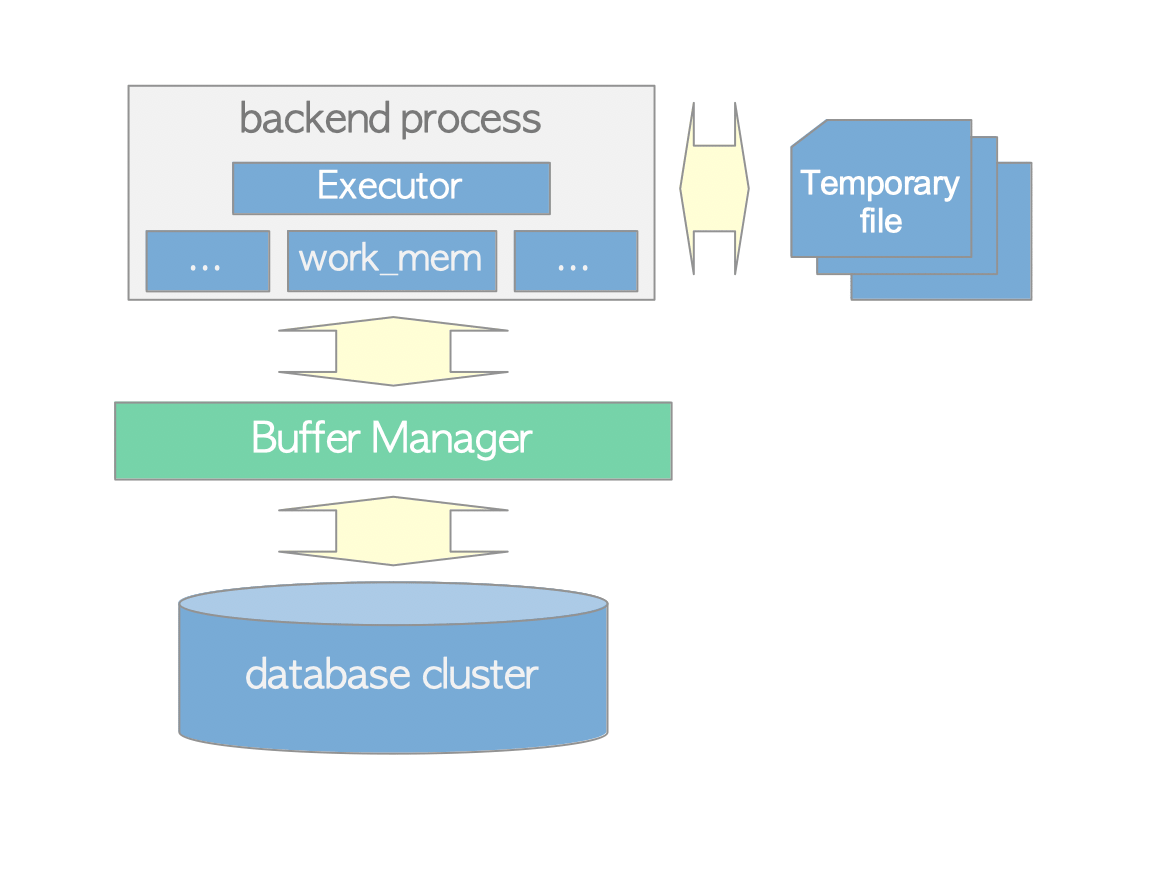
Query z hľadiska systému
Ukazuje obrázok. Dotaz je vykonávaný exekutorom vo work_mem, doptáva sa bufferu a prípadne i priamo DB súborov (čítanie z disku). Ak work_mem nestačí, tak sa medzivýsledky ukladajú do temp súborov.
Cost based
Cost (nákladnosť prevádzkového plánu dotazu) je bezrozmerná veličina (nie sú to milisekundy). Pozostáva z 3 častí: start cost, run cost a total cost. EXPLAIN ukazuje prvú a poslednú:
Seq Scan on tab (cost=0.00..65.00 rows=3000 width=16) —> sekvenčný sken tabuľky má start cost 0 a total cost 65. (v skutočnosti Postgres netuší, či číta bufferd data, alebo tuples z disku).
Samotný EXPLAIN má mnoho podob, najčastejšou je asi ANALYZE (viď nižšie). Zaujímavou fičúrou, ktorá popiera to, čo som pred chvíľou napísal je BUFFERS (hit, dirtied atd…)
Costs sú počítané touto C rutinou – v zdrojáku sú uvedené funkcie jednotlivých typov čítania dát (seqscan() a pod.).
EXPLAIN ANALYZE
Zatiaľčo explain uvádza len bezrozmerné costy nejakej operácie, EXPLAIN ANALYZE (okrem toho, že zbehne dotaz) ukáže aj run time, row number a veľkosť temp súborov, pokiaľ work_mem nestačila.
POZOR!!! Zatiaľčo EXPLAIN ukáže len prevádzkový plán, EXPLAIN ANALYZE skutočne dotaz realizuje – výstup je potlačený (resp. ukáž elen jeho costs), ale dotaz zbehne, takže pokiaľ robíte nejaký INSERT, tak sa data skutočne insertnú….
PG_CATALOG
Na základe čoho sa EXPLAIN rozhoduje, keď zostavuje exekučné plány_ Na základe štatistík, ktoré sú storované v katalógu pg_statistic a ten sa plní príkazom ANALYZE, alebo v priebehu autovaccua.
Tam jenom upresneni – executor jede shora – evaluace bezi od korene k listum. Executor musi proiterovat k listum, kde jsou data, ktera se pak postupne volaji jako vysledek jednotlivych operaci.
Pavel Stěhule
29 Apr 21 at 5:51
Děkuji, mistře, opraveno. Má to logiku.
ďobo
5 May 21 at 9:00
V prípade, že chce človek u queries mať aj nejaké info o I/O časoch, je vhodné použiť paramaeter track_io_timing
https://malisper.me/track_io_timing/
dobo
30 Jun 21 at 7:29