Postgres – vsetko, co si chtel vediet, ale bal sa spytat svojho seniora, aby si nevypadal ako jelito 04. Wal logy.
Wal logy su REDO logy, alebo inak boli nazyvane aj Xlogy, a su to vlastne transakcne logy :). Takze teraz poporiadku – co su v Oracle REDO logy, su v Postgrese WAL logy. Do verzie 10 v tom bol naming chaos, nakolko sa nazyvali Xlogy.
Princip
Princip WAL logov je zalozeny na myslienke, ze ked databaza zbuchne, tak transakcie, ktore nie su zapisane do datafilov (su zatial v shared buffer pool), su zachranene, lebo su zapisane do redo logov a preto sa po zbuchnuti daju obnovit. Podobne, ak pride k chybe pri zapise do datafilov a tie su corrupted, tak sa da vratit k poslednemu checkpointu a dohrat to WAL logmi. WAL znamena Write Ahead Log. Otazka – no a aky je rozdiel medzi zapisom do datafilov a do wal logov? V podstate ziadny, okrem rychlosti. Takze wal logy garantuju urcitu bezpecnost dat bez znizenia performance:
- wal segmenty sa zapisuju do binarneho suboru logu sekvencne (za sebou) a nie random I/O, ako v pripade zapisu na disk (checkpointu), preto je to hrozne rychle.
- zapisuju sa tu len delty dat, jednotlive transakcie a nie cely blok dat ako v pripade datafilu, preto je to tak rychle. Checkpoint prepise cele bloky dat v datafilu, walwriter len transakcnu zmenu.
- zapis do wal logu sa vykonava okamzite po nejakej zmene – ovsem pred potvrdenim transakcie. To preto, aby boli zmeny neakceptovane v pripade padu databaze (= commit sa “odohraje” az ked je zmena zapisana do wal logu)
- wal record sa uklada do wal logu pomocou systemoveho
fsync - statistiky WAL zurnalu je dobre cekovat viewom
SELECT * FROM pg_stat_wal;
vztah commitu a wal logu
Postupnost zapisu a vztah ku commitu je klucovy pre durabilitu dat a konzistenciu udajov (= klientovi nie je potvrdeny commit pokial to nie je bezpecne ulozene do wal logu):
- spusti sa transakcia, nieco robi (napr. INSERT), je viditelna len pre tento proces. Wal writer urobi zaznam do wal logu “tu bolo insertnute toto”
- postgresql proces to zapise, ale fakticky to nie je commitnute, pokial wal writer nepotvrdi, ze je to ulozene vo wal logu (
synchronous_commit = on—> default nastavenie, ale da sa zrusit!) - ked to wal writer potvrdi, postgres oznaci transakciu za commitnutu (viditelnu pre inych uzivatelov) a klientovi povrdi uspesny COMMIT
WAL a LSN
Log Sequence Number (LSN) je číselná hodnota, ktorá označuje určitú pozíciu v WAL logu. Vlastnosti:
- LSN predstavuje byte offset od začiatku WAL logu a používa sa na označovanie jednotlivých záznamov. Ukazuje na presnu poziciu v ramci WAL logu (napr 0/162C1D28 ukazuje, ze ide o segment 0000001 a hexa poziciu 162C1D28)
- Záznamy v WAL logu sú ukladané sekvenčne, takže každý záznam má unikátne LSN.
- Kazda commit transakcie ma vlastne LSN
- LSN ma velky vyznam pre replikacie, kde si procesy na jeho zaklade overuju, co bolo a co nie odreplikovane.
- LSN sa uklada aj do checkpointu a podla toho DB pri obnove vie, odkial ma dohrat udaje z WALu.
Jak zistit aktualny LSN: SELECT pg_current_wal_lsn();
Jak zistit posledny LSN checkpointu: SELECT checkpoint_lsn FROM pg_control_checkpoint();
Jak zistit, o kolko je replika za masterom:
SELECT pg_wal_lsn_diff(
pg_current_wal_lsn(),
replay_location
) FROM pg_stat_replication;
Ako citat obsah WALu
No, je to kvoli efektivite binarny zapis, takze priamociaro to nejde. V zasade poznam 3 postupy:
- pomocou utility pg_waldump. Priklad: co bolo zmenene transakciou 123456:
pg_waldump | grep "tx: 123456" - pomocou pg_walinspect
- pomocou logical decoding, funkciou
pg_logical_slot_get_changes. Cely postup:
- je nutne vytvorit replikacny slot:
SELECT pg_create_logical_replication_slot('test_slot', 'test_decoding'); - je mozne citat priamo SQL zaznamy na pozicii slotu:
SELECT * FROM pg_logical_slot_get_changes('test_slot', NULL, NULL);
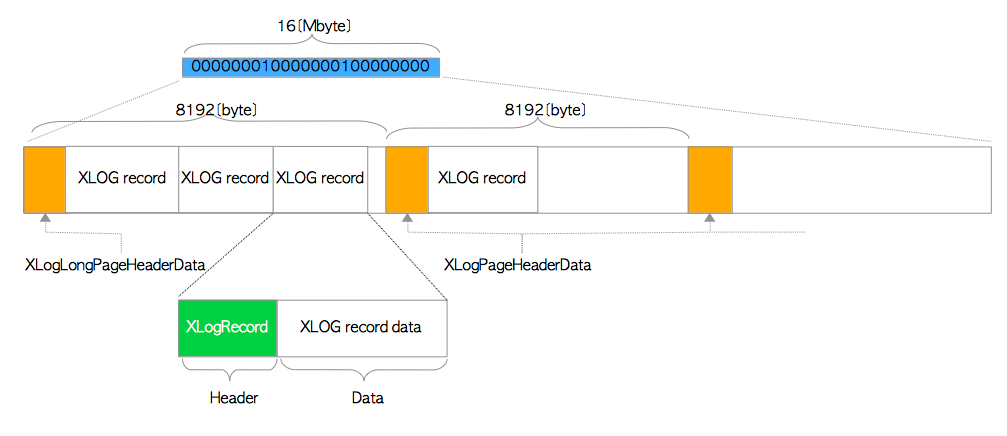
Struktura WAL logu
Najdolezitejsi part wal logu je tzv. XLOG record – de facto zmenovy datovy udaj, sparovany s LSN. Wal logy obsahuju aj udaj o checkpointe (kedy a kde), t.j. kedy bol naposledy zapisany do datovych fajlov REDO point.
Wal logy su 16 MB subory, ich nazov sa vytvara pomocou tejto kuzelnej formulky:
WAL segment file name=timelineId+(uint32)LSN/116M∗256+(uint32)(LSN/116M)%256
Procesy
Wal writer – zapisovac XLOG zaznamov do wal logov. Defaultne kazdych 200 milisekund a neda sa disablovat (len zmenit interval v konfiguraku)
Checkpoint proces zapisuje checkpointy z wal logov a to defaultne kazdych x sekund (premenna checkpoint_timeout), alebo ked stupne velkost wal logov nad x GB (premenna max_wal_size). Okrem toho, ze zapise REDO point do storage, zapise ho aj do pg_control filu, ktory je klucovy v pripade restoru. Pozor, pg_control je binarny subor, cita sa utilitou pg_controldata
checkpoint
Checkpoint je zapis spinavych pamatovych bufferov (shared buffers) do datafilov. Je to metoda, jak urobit data persistent (napr. pri vypadku prudu; aj ked to nie je uplne pravda, pretoze data su uz zapisane vo WAL logoch) a hlavne urobit bod, z ktoreho sa bude pripadne databaza recoverovat. Z zasade existuju 2 druhy checkpointov:
- timed checkpoint = zapisuje sa pravidelne v intervale definovanom v postgresql.conf
- requested checkpoint = zapisuje, pokial sa naplni (a switchne) WAL log, alebo pokial sa checkpoint vynuti prikazom
CHECKPOINT; requested checkpointov by malo byt radovo mensi pocet, nez timed
Ako prebieha zapis checkpointu:
- robi ho proces checkpointer, ktory bude zapisovat len tie buffery, ktore su oznacene ako zmenene
- samotny checkpoint je rozlozeny v case (
checkpoint_completion_target) a postupne zapisuje. - start checkpointu je zapisany do WAL logu a do kontrolneho suboru (/global/pg_control) – bude tvorit bod, od ktoreho sa bude obnovovat po pripadnom pade
- start aj dokoncenie checkpointu moze byt logovane (
log_checkpoints = on)
WAL switching a archivacia
WAL logy sa switchuju (nieco ako logrotate), a to ked sa a) zaplni, b) ked sa zavola funkcia pg_switch_xlog, alebo c) alebo sa vyvola archivacia wal logu. Vzhladom na to, aku dolezitu ulohu maju WAL logy (je to zurnal vsetkych dat), tak je zahodno ich priebezne niekam archivovat a v pripade potreby (restore) opat nahrat do DB a tym sa dostat k ziadanemu bodu stavu DB. Odlievaniu logov sa odborne hovori wal archiving, ale v principe je to vlastne inkrementalny backup :). V pripade real-timoveho odlievania logov je to replikacia.
V okamihu, ked dojde ku switchu wal logu, alebo je evokovany komand archivovania, dojde k odlietiu wal logu na miesto zalohy. Je to konfigovane v hlavnom konfiguraku postgresql.conf a pouzivaju sa na to normalne unixove utility (e.g. archive_command = 'cp %p /home/postgres/wal_archives/%f'). Dobrou praxou je archivovat na nejaky bezpecny nfs share a tak.
Priklady:
# Copy the file to a safe location (like a mounted NFS volume)
archive_command = 'cp %p /mnt/nfs/%f'
# Not overwriting files is a good practice
archive_command = 'test ! -f /mnt/nfs/%f && cp %p /mnt/nfs/%f'
# Copy to S3 bucket
archive_command = 's3cmd put %p s3://BUCKET/path/%f'
# Copy to Google Cloud bucket
archive_command = 'gsutil cp %p gs://BUCKET/path/%f'
# An external script
archive_command = '/opt/scripts/archive_wal %p'
Ine dolezite parametre wal archivovania (v postgresql.conf):
- v pripade externeho skriptu pouziteho pre archiving je dolezite, aby ho mohol spustit user postgres
- wal log bude oznaceny ku zmazaniu, ak bol sprocesovany (odarchivovany) skriptom. Nie je tam nijaka pokrocila logika – skript musi vratit 0 a pokial nie, tak je znova a znova spustany s nadejou, ze dobehne s 0
- do skriptu je velmi uzitocne zapracovat podmienku proti prepisu wal logov s rovnakym menom
min_wal_sizeamax_wal_size– tymto obmedzenim je mozne udrziavat wal logy v rozumnej velkosti a vynucovat ich switchovanie v rozumnom case.
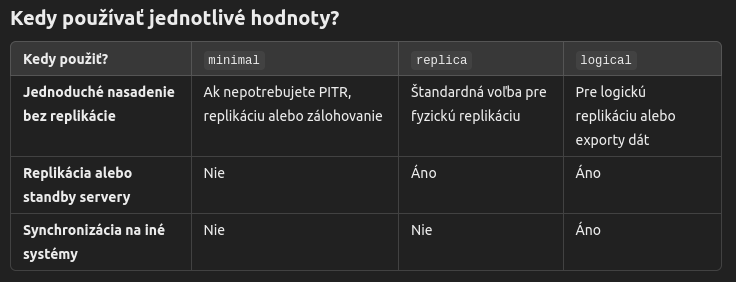
WAL level
wal_level (v postgresql.conf) oznacuje typ struktury wal logu (minimal, replica, or logical), resp mnozstvo udajov, ktore je do logu zapisovane. Minimal poskytuje len zakladne datove udaje a staci pre obnovenie z crashu databaze, ale neumoznuje archiving (pokial je archive_mode = on, tak wal_level musi byt aspon replica). Replica je pre fyzicku replikaciu a PITR, logical level je vyzadovany pre logicku replikaciu: